Architecture
Immich uses a traditional client-server design, with a dedicated database for data persistence. The frontend clients communicate with backend services over HTTP using REST APIs. Below is a high level diagram of the architecture.
High Level Diagram
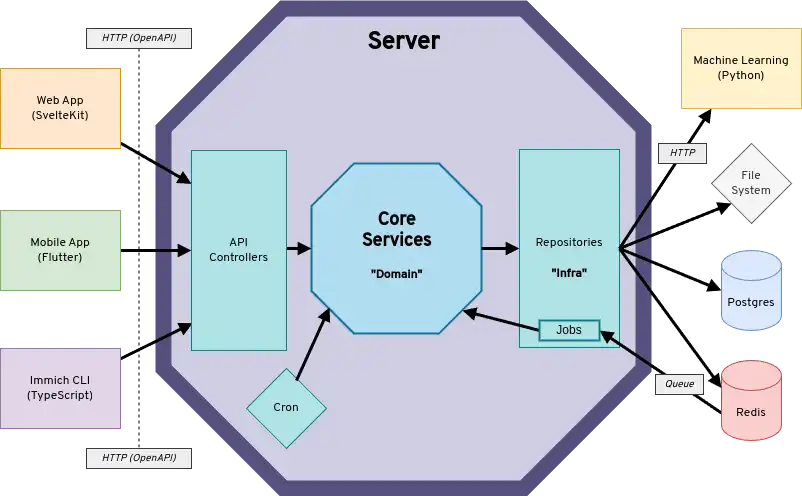
The diagram shows clients communicating with the server's API via REST. The server communicates with downstream systems (i.e. Redis, Postgres, Machine Learning, file system) through repository interfaces. Not shown in the diagram, is that the server is split into two separate containers immich-server and immich-microservices. The microservices container does not handle API requests or schedule cron jobs, but primarily handles incoming job requests from Redis.
Clients
Immich has three main clients:
- Mobile app - Android, iOS
- Web app - Responsive website
- CLI - Command-line utility for bulk upload
Mobile App
The mobile app is written in Dart using Flutter. Below is an architecture overview:
The diagrams shows the target architecture, the current state of the code-base is not always following the architecture yet. New code and contributions should follow this architecture. Currently, it uses Isar Database for a local database and Riverpod for state management (providers). Entities and Models are the two types of data classes used. While entities are stored in the on-device database, models are ephemeral and only kept in memory. The Repositories should be the only place where other data classes are used internally (such as OpenAPI DTOs). However, their interfaces must not use foreign data classes!
Web Client
The web app is a TypeScript project that uses SvelteKit and Tailwindcss.
CLI
The Immich CLI is an npm package that lets users control their Immich instance from the command line. It uses the API to perform various tasks, especially uploading assets. See the CLI documentation for more information.
Server
The Immich backend is divided into several services, which are run as individual docker containers.
immich-server- Handle and respond to REST API requests, execute background jobs (thumbnail generation, metadata extraction, transcoding, etc.)immich-machine-learning- Execute machine learning modelspostgres- Persistent data storageredis- Queue management for background jobs
Immich Server
The Immich Server is a TypeScript project written for Node.js. It uses the Nest.js framework, Express server, and the query builder Kysely. The server codebase also loosely follows the Hexagonal Architecture. Specifically, we aim to separate technology specific implementations (src/repositories) from core business logic (src/services).
API Endpoints
An incoming HTTP request is mapped to a controller (src/controllers). Controllers are collections of HTTP endpoints. Each controller usually implements the following CRUD operations for its respective resource type:
POST/<type>- CreateGET/<type>- Read (all)GET/<type>/:id- Read (by id)PUT/<type>/:id- Updated (by id)DELETE/<type>/:id- Delete (by id)
Domain Transfer Objects (DTOs)
The server uses Domain Transfer Objects as public interfaces for the inputs (query, params, and body) and outputs (response) for each endpoint. DTOs translate to OpenAPI schemas and control the generated code used by each client.
Background Jobs
Immich uses a worker to run background jobs. These jobs include:
- Thumbnail Generation
- Metadata Extraction
- Video Transcoding
- Smart Search
- Facial Recognition
- Storage Template Migration
- Sidecar (see XMP Sidecars)
- Background jobs (file deletion, user deletion)
This list closely matches what is available on the Administration > Jobs page, which provides some remote queue management capabilities.
Machine Learning
The machine learning service is written in Python and uses FastAPI for HTTP communication.
All machine learning related operations have been externalized to this service, immich-machine-learning. Python is a natural choice for AI and machine learning. It also has some pretty specific hardware requirements. Running it as a separate container makes it possible to run the container on a separate machine, or easily disable it entirely.
Each request to the machine learning service contains the relevant metadata for the model task, model name, and so on. These settings are stored in Postgres along with other system configs. For each request, the microservices container fetches these settings in order to attach them to the request.
Internally, the machine learning service downloads, loads and configures the specified model for a given request before processing the text or image payload with it. Models that have been loaded are cached and reused across requests. A thread pool is used to process each request in a different thread so as not to block the async event loop.
All models are in ONNX format. This format has wide industry support, meaning that most other model formats can be exported to it and many hardware APIs support it. It's also quite fast.
Machine learning models are also quite large, requiring quite a bit of memory. We are always looking for ways to improve and optimize this aspect of this container specifically.
Postgres
Immich persists data in Postgres, which includes information about access and authorization, users, albums, asset, sharing settings, etc.
See Database Migrations for more information about how to modify the database to create an index, modify a table, add a new column, etc.
Redis
Immich uses Redis via BullMQ to manage job queues. Some jobs trigger subsequent jobs. For example, Smart Search and Facial Recognition relies on thumbnail generation and automatically run after one is generated.